
As per Gartner, 65% of world population’s data will be impacted due to privacy regulations by 2023. In fact, it might happen sooner as most countries wish to provide economic nationalism by restricting cross country data transfers and data rationing by global technology businesses.
Another Independent trend coupled with the rise of tighter privacy regulations is the volume of unstructured data being collected. it is estimated that about 60-80% of the overall data stored today is unstructured. Combined, both structured & unstructured data are projected to grow at the rate of 7-12% on an annual basis.
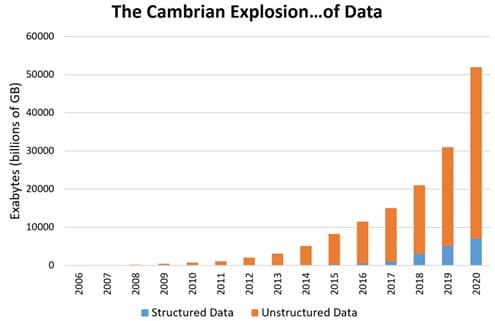
Technological advances along with ever falling storage prices have made it quite easy to collect unstructured data from the customers. And businesses are mining this data at far greater levels than before to gain competitive advantage. With the rise of social media, messaging and multiple modes of communication there is a significant rise in the collection of personal data about users’ preferences, buying behaviors and activities.
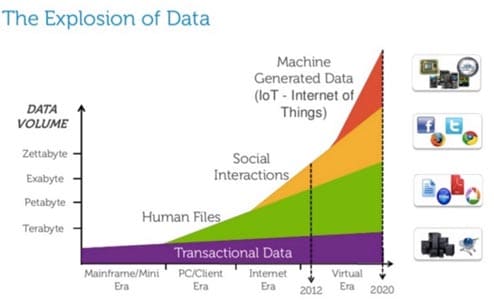
Sources with unstructured data
The sprawls of unstructured data includes customer transactions, chat, online communities, service notes, social media, voice transcriptions, call center notes, ratings/reviews and email. These sources integrate and have pointers to records stored in structured databases today and it becomes quite complex and overwhelming to detect, manage and monitor. It is fairly common where CRM systems would ingest unstructured text from messaging systems such as Slack or Facebook feeds for improving customer service.
Within these sources, the kind of information is quite varied from textual emails to FedEx PDF receipts, image formats, medical images, binary genome sequences, Twitter feeds and the list continues. In terms of variety of data sources, privacy data is scattered across in documents, messaging systems like Slack and Microsoft Teams, service tickets in Servicenow, Salesforce & Zendesk. One of the most common and largest sources would be emails containing not only customer data but employee resumes, payroll information along with backup & archival storage for these. Imagine a situation where there is a data deletion request against an employee data which is typically quite widespread in multiple sources.
Even with structured sources, data copy or deletion requests for personal data for small and medium businesses take 172 hours to fulfil vs 1,300 hours for larger enterprises. Besides, finding data manually is error-prone. Businesses might miss personal information for privacy data requests. Here automations and AI would greatly help. If we go beyond the fulfillment of privacy data requests and focus on the data security and compliance perspective, the risks and costs associated are much higher.
Current mechanisms for data protection
Many businesses have installed Data Loss Prevention (DLP) Systems, Endpoint Protection Systems or Cloud Access Security Broker (CASB) to detect and prevent leakage of private or sensitive information in databases, emails or network traffic. While these tools are mature and can detect sensitive data to an extent, the features or lack of are:
- DLP and other security tools create a conflict of interest against business objectives by restricting data sharing.
- Pattern-based cybersecurity tools fail to correlate and identify an individual’s information for privacy requests especially between multiple sources,
- Volume and scale of documents in SaaS apps is tough to monitor and restrict how much and whose information is being shared with a rules-based system.
- Cybersecurity tools are evolving to search, identify and correlate personal data in SaaS apps.
- Lack of support for scanning data at rest especially unstructured data. thus increasing the risk of sensitive information accumulation and risks associated with it.
- Lack of support to detect privacy risk in real time and consent management workflows
Cybersecurity tools are more focused on detecting and securing the information whereas sales/marketing and other departments need as much information as possible which can be correlated with a customer for commercial purposes. Security tools’ pattern matching approach cannot identify the purpose and business use of data. Hence, it is nearly impossible to identify and correlate privacy data using current tools. This requires a new approach for fulfilling privacy requirements.
Privacy workflows for unstructured data
To handle unstructured data and be compliant with privacy regulations, businesses need to:
- Choose tools which provide mechanisms for detecting and handling sensitive information
- Choose data discovery software which can efficiently handle raw text preferably without a lot of rules and manual workflows
- Assess risk and DPIAs especially for unstructured sources
- Create and manage data retention policies for text data including email & files
AI to the rescue for handling unstructured privacy data
Use of AI to find sensitive data came into prominence by various eDiscovery tools which used supervised learning along with pattern-based searching approaches to find sensitive data. However, these relied on distance-based approaches which provided them similar efficacy to DLP solutions above. Further, supervised approaches fail to find new sensitive data, not seen before, requiring constant maintenance and upkeep similar to rule-based approaches.
In the last few years, the technology for parsing and understanding language including context derivation has been improved a lot. Rise of transformer-based approaches such as BERT & CNN-based models, which are being used in chatbots, translation and sentiment analytics, have exponentially evolved. These approaches have enhanced our capabilities in natural language understanding (NLU) via sequential modeling, semantic classification, cross-domain analytics and have provided auxiliary capabilities in our identification of privacy data, its context and underlying use.
The newer deep learning algorithms, if done correctly, are efficient, cheaper to deploy and can dramatically reduce false positives, cut down on efforts and reduce errors for finding privacy information & correlation. as our data volumes increase exponentially, we need solutions which can assist us in managing these resources cheaply and with less overhead as possible.
The area of deep learning-based NLU is still evolving. We need an AI Software which can not only understand the language but also the usage & access patterns and map user attributes across multiple data sources. Buyers need to beware of false marketing of AI hype and the privacy industry lacks benchmarks for determining the quality and reliability of the AI platforms.
Meanwhile, DPOs and CSOs need to evaluate and test these platforms against their own datasets to determine the efficacy of discovery mechanisms. Manual workflows or any rule-based custom training should be a red flag for an inefficient data discovery platform. Unless AI is reducing efforts, saving costs and minimizing errors, the automation introduced is not worthy of purchase.
AI beyond privacy data discovery
Besides introducing automations to augment efforts and reduce errors, the new AI-based data discovery mechanisms also assist in providing details about:
- Scope and extent of privacy information being collected
- Risk associated with the data source
- Accurate data maps for unstructured sources rather than survey-based
- Confidence that business is in control of underlying risks in case of breaches
- Faster response times to customer requests and near real-time fulfilment of DSAR is possible.
With newer approaches, AI will be able to assist much better in data governance tasks so businesses can have peace of mind. However “assisted” intelligence still requires human intervention though to a far lower human scale. For the enthusiasts, projects like OpenAI are providing ethical and unbiased understanding of language entities, purpose and context.
We are still in the early phase of privacy data discovery with contextual insights. This is a great starting point like assisted driving is and future AI driven approaches will need to make it easy and affordable for businesses to discover & balance privacy data collection vs risks involved.