
The recent 50 Million Euro Google GDPR fine changes how every organization must do business around the globe. This is due to new requirements for consent under the EU General Data Protection Regulation (“GDPR”) as outlined by Giovanni Buttarelli, European Data Protection Supervisor. Companies must focus on more than consent to legally process analytics and AI when those processes cannot be described with the required specificity and voluntariness at the time of data collection.
You can no longer use consent to:
- Process data collected with non-compliant consent;
- Process “Analytics & AI” (as defined below); or
- Make decentralized Analytics & AI legal.
Most historical data, Analytics & AI, and decentralized processing is illegal under the GDPR. If your organization is relying on consent for any (all?) of these processes, you are in violation of the GDPR.1
[bs-quote quote=”I estimate that 90% of global Analytics & AI are illegal under the GDPR.” style=”style-10″ align=”center” author_name=”CEO” author_job=”Top 10 IT Company”][/bs-quote]
Detailed analysis
1) You Can No Longer Store or Process Data Collected Using Non-Compliant Consent
Data (including historical data) that was collected using outdated “general broad-based consent” is no longer legal to “process” – which under the GDPR includes storing data, whether in encrypted or decrypted form. As a result, such data must be (i) deleted, (ii) anonymized (prohibiting any future re-linkability to identifying data, severely reducing its value), or (iii) transformed to support a new legal basis. For the reasons outlined below, the best alternative is to transform the illegal data by using GDPR compliant Pseudonymization to support Legitimate Interest processing as an alternative (non-consent) legal basis.
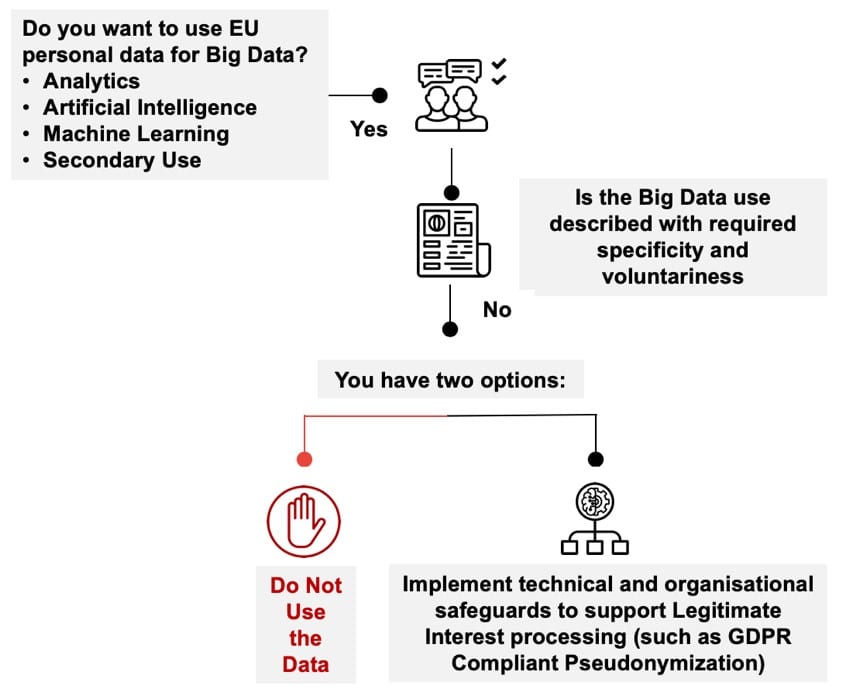
2) You Can No Longer Legally Process Analytics & AI Using Consent
For these purposes, “Analytics & AI” is defined as analytics and AI that cannot be described with GDPR required specificity and voluntariness at the time of data collection – which is mostly the case with secondary processing like analytics and AI. Data controllers can no longer rely on consent for Analytics & AI processing like they did before the GDPR. Under the GDPR, new technical and organizational safeguards are now required to enable legal Analytics & AI processing. In addition, Analytics & AI processing that goes beyond the scope of the original purpose for which the data was initially collected is treated as “further processing” under the GDPR. As more fully described below, to be legal under the GDPR, Analytics & AI processing must include technical and organizational safeguards to ensure that the processing is:
- Lawful under GDPR Article 5(1)(a);
- Compatible processing under GDPR Article 5(1)(b); and
- Limited to processing only the data that is required to support the authorized purpose using Data Minimization techniques under GDPR Article 5(1)(c) and Data Protection by Design and by Default under Article 25.
Under the GDPR, to lawfully include personal data in Analytics & AI processing, it should be ‘Functionally Separated’ to isolate the information value of the data from the means of linking the data to individual data subjects. Also, technical and organisational safeguards should ensure that the processing is compatible with the original purpose for data processing and to enforce data minimisation – all to make the Analytics & AI processing privacy-respectful.

- Consent No Longer Supports Lawful Analytics & AI Processing – Article 5(1)(a): Consent as defined under Article 6(1)(a) the GDPR does not support the lawful processing of Analytics & AI. Rather, Legitimate Interest processing under GDPR Article 6(1)(f) is needed to support legal Analytics & AI processing. To use Legitimate Interest as an alternative (non-consent) legal basis for Analytics & AI processing, data controllers must satisfy a “balancing of interest test” that requires “functional separation” (separation of the information value of data from the identity of data subjects) to reduce the negative impact on data subjects so that the data controller’s legitimate interests are not overridden. Recent high-profile lawsuits against Oracle and Acxiom make it clear that simply claiming a “legitimate interest” in commercializing personal data is not enough.[6] Functional separation capabilities of GDPR compliant “Pseudonymization” are discussed in 3 below.
- Compatible Further Processing Requires Pseudonymization or Encryption – Article 5(1)(b): GDPR Article 6(4)(e) specifies the safeguards for further processing to be considered a compatible purpose when not based on consent. Article 6(4)(e) identifies two technologies – “Pseudonymization” and “Encryption” as technical safeguards that help to ensure that Analytics & AI processing is “compatible.”
- Pseudonymization is Required When Encryption Does Not Support Selective Use – Article 5(1)(c) and Article 25: While encryption is useful for protecting the entirety of a data set, it generally does not support selective granular control over the use of data as necessary to comply with Data Minimization obligations under GDPR Article 5(1)(c) and Data Protection by Design and by Default requirements under GDPR Article 25. As a result, GDPR compliant “Pseudonymization” is often required for Analytics & AI processing to constitute lawful compatible processing.
3) You Can No Longer Use Consent to Overcome Shortcomings of Technologies That Don’t Protect Decentralized Processing
Before the GDPR, receiving consent from data subjects could help to overcome the shortcomings of Privacy Enhancing Techniques (“PETs”) that only protect data when it is used for operational or centralized Analytics & AI processing.[7] Consent was necessary because the common sharing and combining of data among third parties nullify the principles relied upon by such PETs. However, the inapplicability of consent exposes decentralized Analytics & AI processing to significant risk and exposure when using these limited purpose PETs.
The diagram below highlights how PETs like Encryption, Static Tokenization and Data Masking are appropriate for protecting operational data uses. However, they do not support the requirements for privacy-respectful Analytics & AI. Similarly, Differential Privacy enables privacy-respectful operational data use and centralized Analytics & AI but does not support lawful decentralized Analytics & AI processing. In contrast, GDPR compliant Pseudonymisation can help to support privacy-respectful processing of all types.
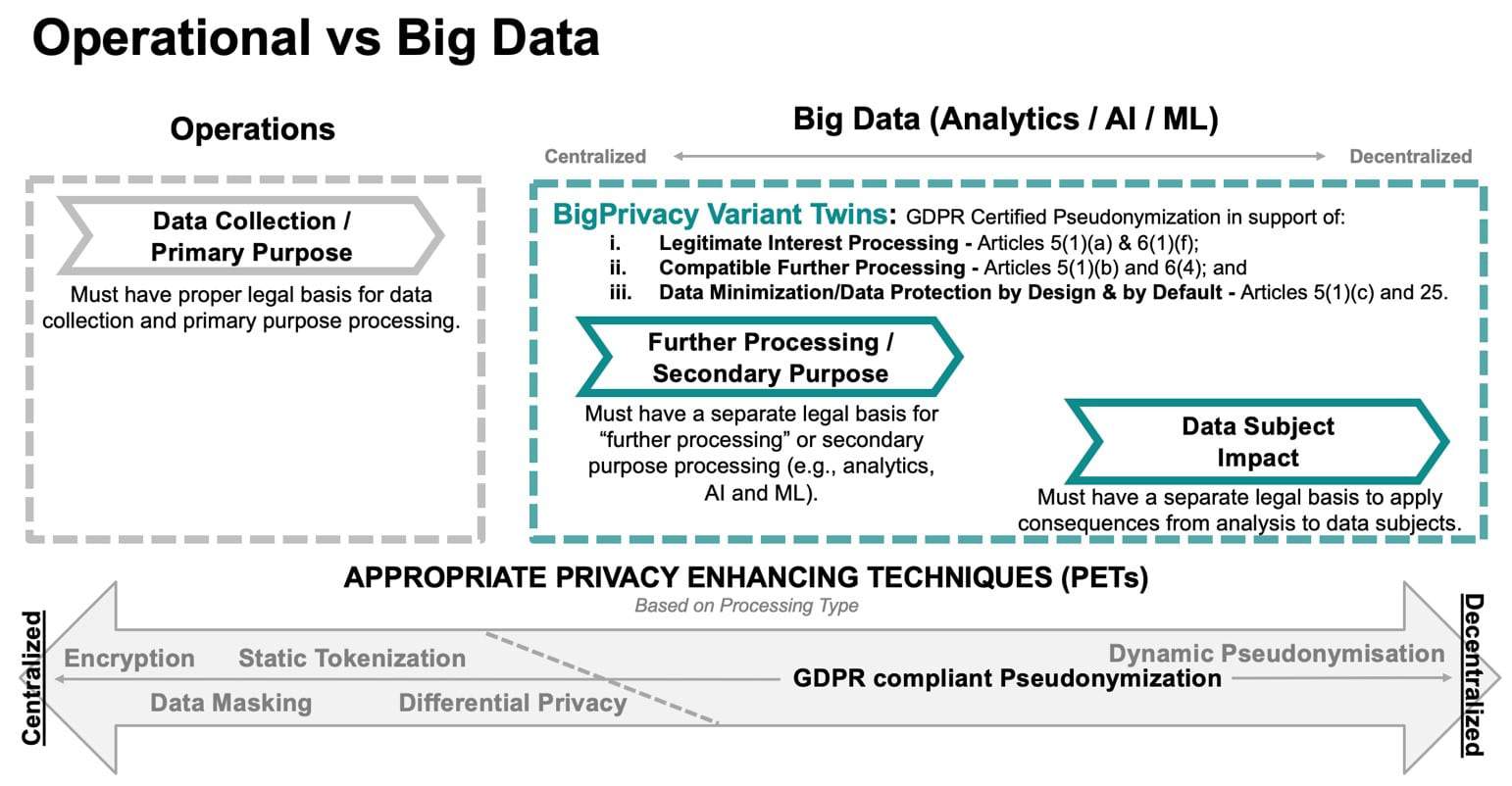
Legal experts have highlighted the potential for new Pseudonymization technologies to address the unique privacy issues raised by Analytics & AI. Pseudonymization has gained attention recently with its explicit codification in the GDPR. Article 4(5) of the GDPR now specifically defines Pseudonymization as “the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person.” Static tokenisation (where a common token is used to replace different occurrences of the same value – e.g., replacing all occurrences “James Smith” with “ABCD”) fails to satisfy GDPR definitional requirements since unauthorized re-identification is “trivial between records using the same pseudonymised attribute to refer to the same individual.” As a result, static tokenisation does not satisfy the “Balancing of Interest” test necessary for Article 6(1)(f) Legitimate Purpose legal basis processing nor is it included in the technical safeguards listed in Article 6(4) to help ensure that Analytics & AI processing is a lawful compatible purpose.
The Article 29 Working Party has highlighted “the special role that safeguards play in reducing the undue impact on the data subjects thereby changing the balance of rights and interests to the extent that the data controller’s legitimate interests will not be overridden” and “safeguards may include technical and organizational measures to ensure functional separation” and ”Pseudonymization…will play a role with regard to the evaluation of the potential impact of the processing on the data subject, and thus, may in some cases play a role in tipping the balance in favour of the controller.” The Article 29 Working Party further highlights that “Functional separation includes secure key-coding personal data transferred outside of an organization and prohibiting outsiders from re-identifying data subject” by using “rotating salts” or “randomly allocated” dynamic versus static, persistent or recurring tokens. GDPR compliant Pseudonymization, therefore, represents a unique means to support lawful Analytics & AI processing by technically enforcing functional separation protection as a supplement to other practical and contractual protection to render unauthorized use of EU personal data difficult or even impossible.
1 The GDPR has jurisdiction over any processing of personal data of individuals who are in the EU at the time of the processing regardless of the nationality of the individual or the location of the organization doing the processing. This applies equally to the offering of goods or services to individuals when in the EU and to monitoring the behavior of individuals that takes place in the EU.