
The recent $414 million fine imposed on Meta by the European Data Protection Board illustrates the discrepancy in the types of data protected under U.S. and EU data privacy laws. Given this fine, it is important to discuss these differences as they have significant implications for companies using data clean rooms, a method that enables advertisers and companies to use user-level data that does not immediately reveal personally identifiable information, which has been receiving a lot of attention recently.
Understanding the difference between PII and personal data
First, let’s look at the difference between the U.S. concept of personally identifiable information (PII) and personal data. PII is data that directly identifies an individual, such as a name, address, social security number or other identifying number or code. PII is only a subset of the information that must be protected under the General Data Protection Regulation (GDPR).
The GDPR requires protection for all personal data, extending beyond PII to encompass indirect identifiers and attributes, specifically including: “any information relating to an identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.”
What is a data clean room?
Next let’s examine what a data clean room is. According to TechTarget, “A data clean room provides aggregated and anonymized user information to protect user privacy, while providing advertisers with non-personally identifiable information (non-PII) to target a specific demographic and for audience measurement.”
Do you see the disconnect? While a clean room may provide a restricted perimeter for data use, which offers more security than the current ad-tech ecosystem, it does not make the processing of EU personal data lawful under the GDPR because it does not protect all of the data covered by the GDPR. Therefore, even if Meta were using a clean room for marketing and advertising purposes, it would not be adequate for GDPR compliance. And without GDPR compliance, Meta can’t claim legitimate interest as a legal basis for lawful secondary processing.
What should lawful secondary data processing look like?
The following graphic, with supporting text, highlights this point by outlining the requirements for lawful secondary processing, including personalization, in the context of selling a trip via a website.
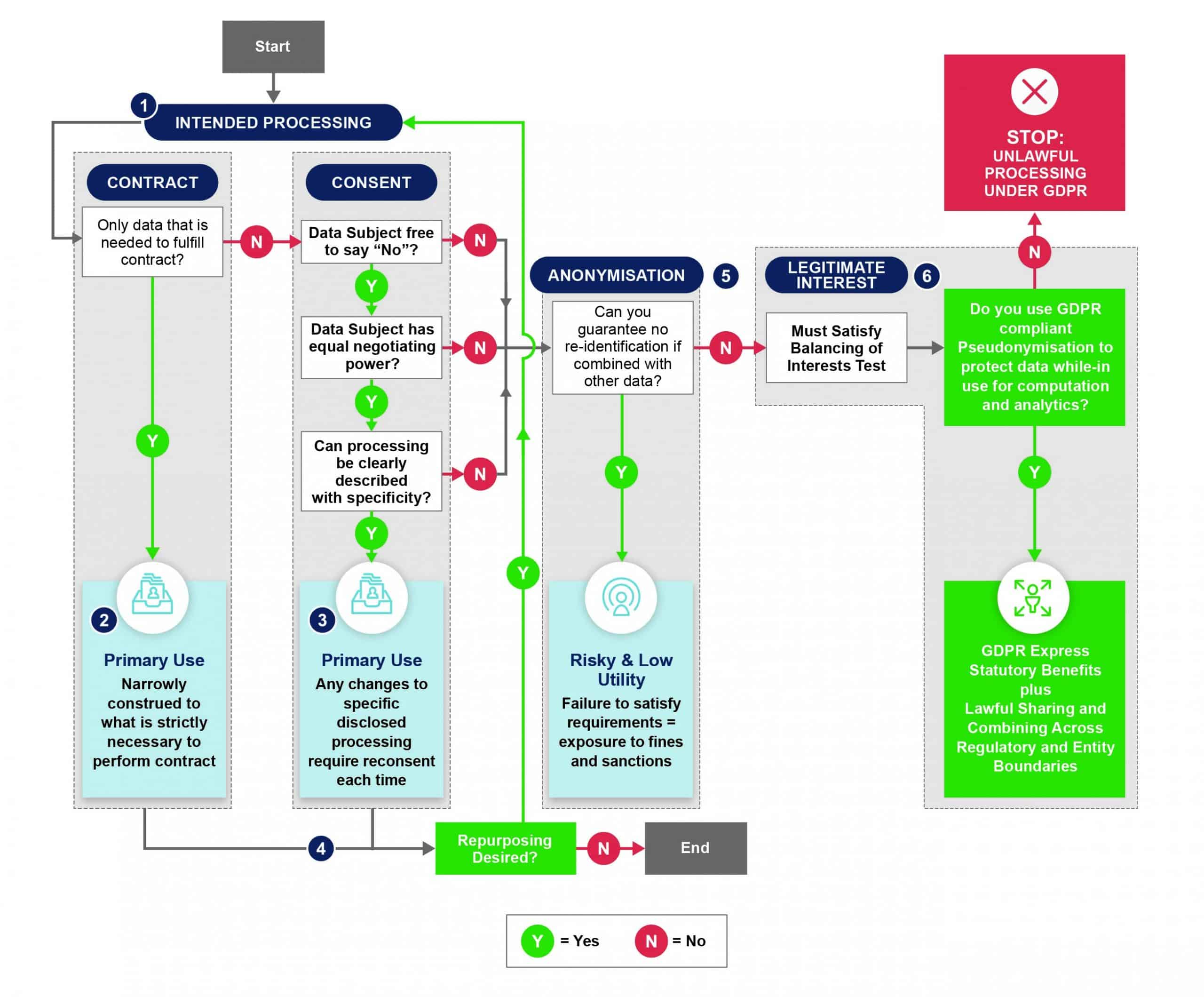
Number references below correspond to references in the figure above.
- Examples of intended purposes
- Sell a trip via a website (flight, hotel, etc.);
- Save preferences for future bookings; and
- Determine and deliver via email personalized future trip offers based on market analytics.
- Under GDPR Article 6(1)(b), using contract (such as attempted by Meta) as a legal basis:
- You can sell an initial trip, but you cannot:
- Save information for future bookings; or
- Market for future trips.
- You can sell an initial trip, but you cannot:
- Under GDPR Article 6(1)(a), using consent as a legal basis:
- You can save preferences for future bookings; but
- This only works for marketing analytics that were disclosed with specificity at the time of initial data collection.
- Any additional marketing would be:
- Further processing/secondary repurposing under contract; and
- Would fail the requirements of advanced specificity under consent;
- This additional processing would require obtaining new consent or a new legal basis.
- Due to the details of the data collected and the need to retain indirect identifiers and attributes unprotected for desired additional marketing, the requirements for anonymization under the GDPR would not be satisfied.
- Under GDPR Article 6(1)(f), legitimate interest remains an available legal basis for lawful marketing analytics. Statutory Pseudonymization, as newly defined in Article 4(5) of the GDPR, protects data when in use for computation and analytics to support lawful legitimate interest processing by tipping the balance in favor of processing by the data controller.
Statutory Pseudonymization: A solution for protecting personal data in use
What technical controls can be implemented to meet the requirements outlined in the above use case? The answer is Statutory Pseudonymization as initially defined under the GDPR and now addressed in an increasing number of newer international and U.S. state privacy laws. All of these laws contain three definitional requirements for Statutory Pseudonymization: (a) the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, (b) storing such additional information separately and (c) imposing technical and organizational measures on such information to ensure that the personal data are not attributed to an identified or identifiable natural person. These requirements can be achieved using a combination of de-identification techniques, dynamic pseudonyms or codes, and separate protection by technical and organizational measures that replace both direct and indirect identifiers of personal data.
With Statutory Pseudonymization, re-identification of individuals is not possible without the use of additional information (keys) that are held separately and securely by the data controller or their designee. The process can be reversed, but only when re-identification of the source data is authorized, with the use of the keys under the control of the data controller, making it an effective solution for use cases where data needs to be shared among multiple parties.
Statutory Pseudonymization fills in the gap between legal requirements and technology enablement by introducing technical controls that travel with data wherever it flows, ensuring it’s protected in use by delinking direct and indirect identifiers. This privacy-enhancing computation technique also provides dynamism to prevent multiple data sets from being recombined to re-identify a data subject, another advantage given all the personal data available in a clean room that could make linkages and inferences likely.
A data clean room offers greater security than the current ad-tech ecosystem and can be used to protect some personal information, but companies need to realize that GDPR requirements go beyond PII, so they can make informed decisions about what technical controls they need to implement to protect any sensitive data.
To learn more about the requirements for and benefits of Statutory Pseudonymization for supporting lawful analytics using GDPR Article 6(1)(f) legitimate interest processing, you can read “Technical Controls That Protect Data When in Use and Prevent Misuse,” recently published in The Journal of Data Protection & Privacy.