
“Data is the new oil” – not only is this an overused expression with over 1 billion hits on Google but it is also a rather inaccurate comparison. If you find a source of oil in your garden today, you could quickly make money out of it. The infrastructure and technology exists, there are experts and customers for all processing steps and by-products. But imagine you instead find a “data pot” which has grown over the years in your company. You can’t simply rely on proven processing chains because new data protection laws make extracting value from this data so hard. All too often decision-makers in companies now face the question: Here I have valuable data, but what next?
Untapped data potential
Of course, some companies have already solved this problem. Google and Facebook, two of the world’s largest companies, came into their current position because of the sheer value of their customers’ data. So, it is hardly surprising that both companies are trying to enrich their already immense data with information from other sources. For example Google now buys data from credit card institutions to combine online advertising with offline purchases. Facebook goes one step further and offers its own customer profiles in exchange for transactional data.
Why are these two big players heading for shallow waters to get your bank account information? Surely Google already knows exactly where I will spend my next vacation? And Facebook can already accurately determine my personality structure because of a few likes? Sure, but my bank knows a lot more. Or at least they could know.
Transactional data can you give you a huge range of interesting insights even with simple methods. Of course, shopping habits and preferences are easily identifiable, but also motion profiles can be created by using the addresses of stores and restaurants you have visited. The amount of child allowance you receive gives a clue to the number of children. Fuel costs indicate kilometers driven and the estimate can be even more accurate if you include the amount of vehicle tax paid.
A complicated way out
In the finance sector, trust is vital, more so than in almost any other field of business. As a customer, I entrust my money to a bank because it is safe there. I implicitly expect the same with my data. But obviously, the abuse potential is enormous.
So, how can banks legally share your transactional data? Anonymization is one legally-supported solution to this. Correctly(!) anonymized data can no longer be traced back to individuals without disproportionate effort, regardless of which additional information an analyst has. Thus, personal data can be safely and legally evaluated. The General Data Protection Regulation (GDPR) specifies in recital 26: “The principles of data protection should […] not apply to anonymous information”.
Well, that sounds like good news. Simply anonymize the data first, and you do not have to worry anymore … Surprisingly, this is not the case.
Typically, there are three problems with anonymization:
- Anonymization is very complex and time-consuming. It is not enough to simply remove obvious identifiers such as names or bank account numbers. For example, in the United States, 63% of citizens are clearly identified just from date of birth, gender and postal code. Even such a simple data set requires profound methods of anonymization, almost always with high manual effort and complex considerations.
- If the anonymization is carried out incorrectly, there is a great risk for those responsible. Under the GDPR, fines can be up to 4% of the annual turnover or 20 million euros (whichever is greater), as has been repeatedly emphasized in recent months.
- However, even if the anonymization was done correctly, there is another serious problem. Data quality usually suffers enormously. Take the aforementioned record of US citizens. Even if you only have the country of origin instead of the zip code, still about 18% of people can still be clearly identified. So you would have to merge more cells in the data set, for example indicate only the birth month instead of the date of birth. The usefulness of the dataset has then suffered a lot1. Data privacy researcher Paul Ohm wrote in 2010: “Data can either be useful or perfectly anonymous – but never both”.
New innovations in data anonymization
The issues above may make it sound like anonymization is pointless. Take for example the infamous “anonymous” taxi record from New York City, which was quickly re-identified after its release in 2014 . CNIL, the French Data Protection Authority, wanted to demonstrate that a true anonymization of this data set is indeed possible. The result is very inaccurate and therefore, unfortunately, unsuitable for most applications.
However, there is a way of anonymizing this data without losing the utility. Using Diffix, an approach we at Aircloak have developed together with the Max Planck Institute for Software Systems, we can create a data set that is just as secure and yet significantly more useful.
In the figure below, the left-hand image shows the NYC taxi data set anonymized by classic approaches. It is clear the data is fairly useless as it now only indicates departure points by postal code areas. The right-hand image shows the same dataset anonymized using Diffix. As can be seen, the data is far more detailed, and hence has greater utility.
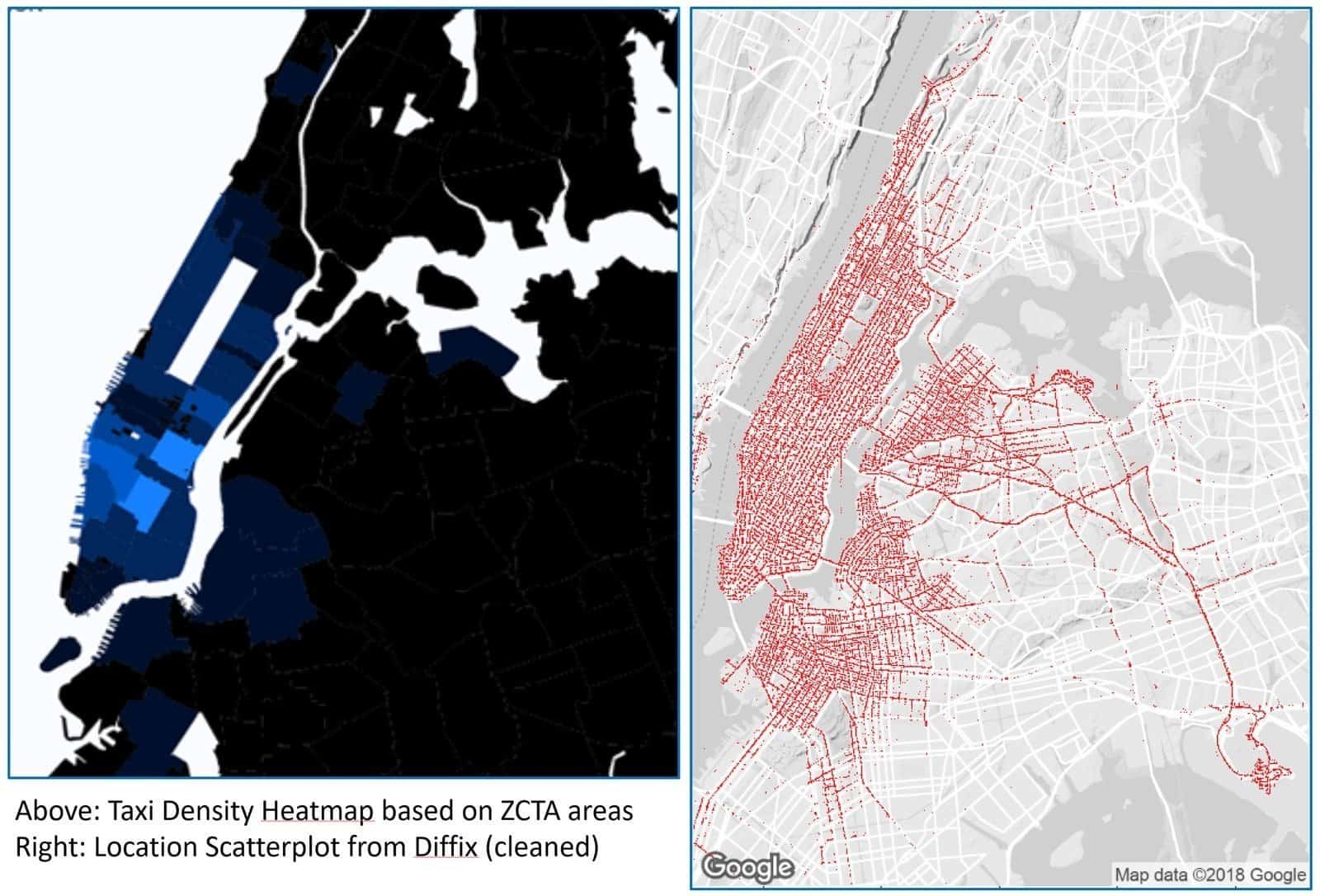
Comparing classic anonymisation with Diffix. These figures come from the article “Can Anonymous Data Still Be Useful? Part Deux ” by Paul Francis.
In contrast to classic anonymization, Diffix does not anonymize the entire data set before the analysis. Instead, it dynamically anonymizes each database query, and adds carefully tailored noise to the query. The approach is already successfully being used in the banking industry to evaluate transaction data, and is also very helpful in the healthcare industry to anonymize patient data. The analysis of such anonymized data sets gives significant potential for improved product development, better marketing and more focused business intelligence. Using descriptive statistics, it is possible to safely determine what the median income of a particular group of users is, even sorted by different banks. Correlations and regressions are also possible: Do people with higher incomes spend more on insurance? When are people most likely to apply for a loan?
Data treasure despite data protection
Whether the comparison between data and oil is adequate or not, a competitive company must develop new data-driven business models and processes. Using modern data protection approaches is not only a legal requirement, it can also help improve your whole data strategy, allowing you to monetize it without risking data security. While naïve and classic anonymization is difficult to achieve and often does not provide good results, modern technologies like Diffix offer the best of both worlds. The GDPR has shaken up the data anonymization industry and it is certain that over the coming years we can expect to see more advanced tools being developed by many suppliers.
The Who’s Who of Data Protection Technologies
Anonymization
In the anonymization process, data is changed in such a way that inference to natural persons is no longer possible or only possible through a disproportionately high effort. This is achieved, by grouping data points together or by adding noise (for example incorrect data) to the data set. Anonymized data are not subject to data protection laws.
Pseudonymization
In the case of pseudonymization, direct identifiers of a data record are deleted and replaced with pseudonyms (for example a telephone number could be exchanged with random digits, or a user ID could be stored instead of a real name). This type of processing preserves much of the value of the data, but is not nearly as secure as anonymization. Therefore, pseudonymous data continues to be considered as personal data under the GDPR.
1 This is a simplified representation of anonymization. Functional algorithms are able to produce anonymized data with significantly less alteration. But the basic problem remains the same.